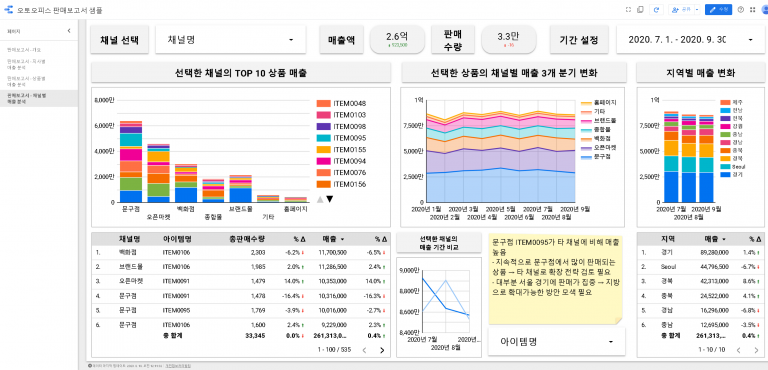
BigQuery: ARIMA 모델 단일 시계열 예측
BigQuery 에서는 로지스틱 회귀분석, 선형회귀분석을 비롯해 다양한 머신러닝 모델링으로 값을 예측을 할 수 있습니다.
이번 포스팅에서는 ARIMA 모델 단일 시계열 예측을 살펴보고자 합니다.
구글 공식 도움말에서는 Google 애널리틱스 360의 데이터를 사용하지만, 모델링이 얼마나 정확한지 보기 위해서 현대자동차의 판매 데이터를 사용했습니다.
1 데이터 준비
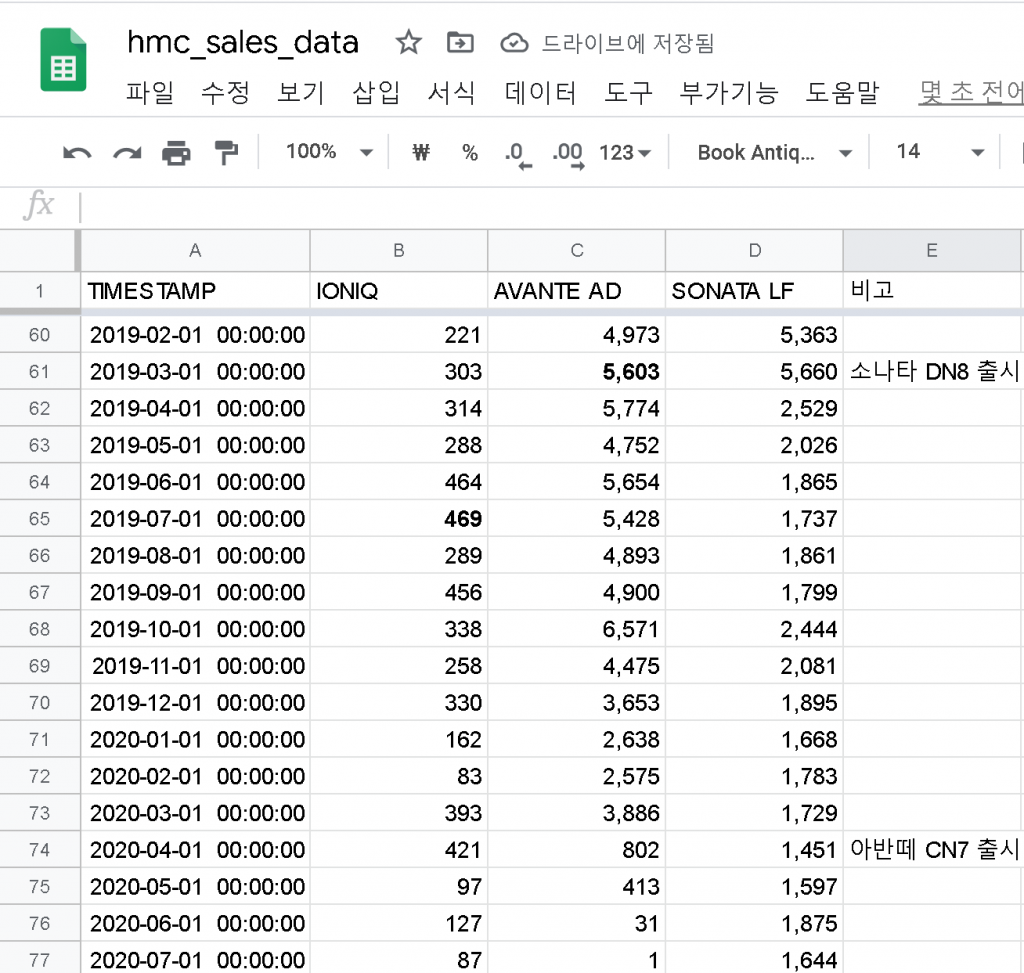
현대자동차의 국내 차종별 판매 데이터를 준비했습니다. IONIQ, AVANTE AD, LF SONATA 차종을 살펴보고자 하는데요.
모델링을 위한 충분한 기간의 데이터가 있고, 예측 결과와 실제값을 비교해볼 수 있을만한 차종으로 보여 선택했습니다.
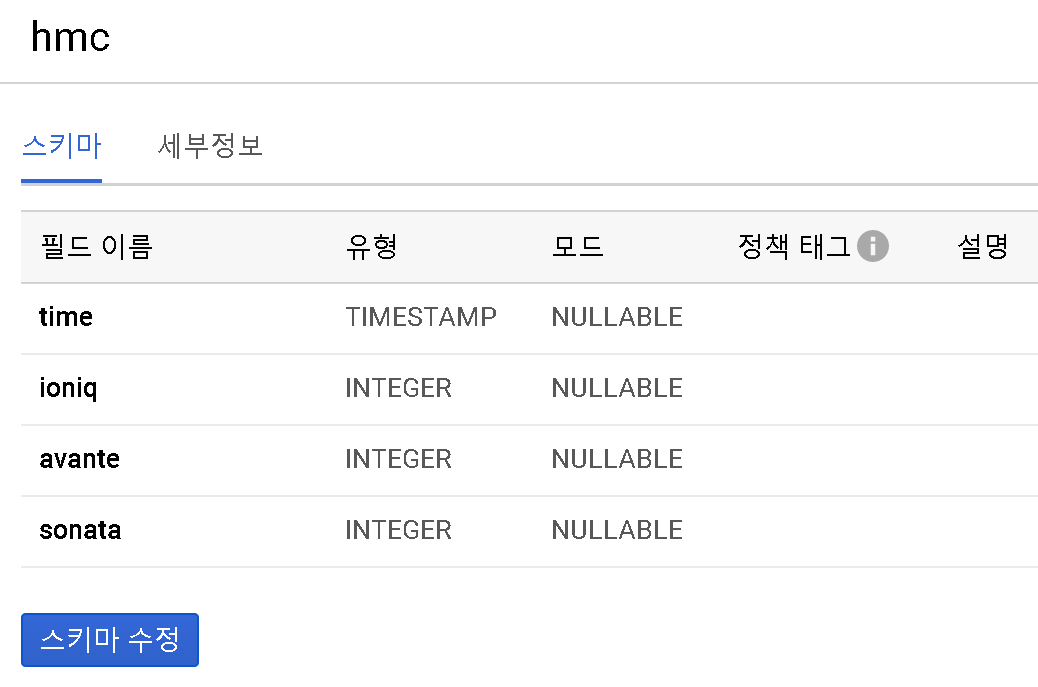
우선 구글 시트로 데이터를 정리하고 빅쿼리에 연결을 진행하여 데이터를 준비합니다.
2 ARIMA 모델링
각 차종별로 ARIMA 모델링을 진행합니다.
데이터로 사용하는 열이 다르고, 그에 따라 모델링도 달라져야하기 때문에, 코드에서 볼드 표시한 부분을 각 차량에 맞게 변경하여 적용합니다.
유의할 점으로 모델링 소스로 사용할 실제 데이터의 time 의 범위를 설정해주었는데요.
IONIQ 은 2019-07-01 까지의 43개의 데이터로 모델링을 세팅해서, 8월부터 12개월의 예측을 진행하고 실제값과 비교합니다.
AVANTE AD 는 2019-03-01 까지의 43개의 데이터로 모델링을 세팅해서, 4월부터 아반떼 신형 CN7 출시월 전까지 12개월의 예측을 진행합니다.
LF SONATA 는 2014-04-01 부터 2018-03-01까지의 48개의 데이터로 모델링을 세팅해서, 2019년 4월부터 2020년 7월까지를 예측합니다. 이 경우는 2019-03에 후속 모델인 DN8 이 출시되었지만, 비교분석을 위해 2020년 7월까지로 세팅했습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#standardSQL CREATE OR REPLACE MODEL bqml_tutorial.ga_arima_model<strong>_ioniq</strong> OPTIONS (model_type = 'ARIMA', time_series_timestamp_col = 'parsed_date', time_series_data_col = 'total_sales' ) AS SELECT time AS parsed_date, SUM(<strong>ioniq</strong>) AS total_sales FROM bqml_tutorial.hmc WHERE <strong>time <="2019-07-01"</strong> GROUP BY time |
모델링에는 오랜 시간이 걸리지 않습니다. 모델링이 진행되고 나면, 테이블이 생성됩니다.

3 ARIMA 모델 기반 예측
이제 모델링으로 예측을 진행합니다.
차량에 따라 코드에서 볼드로 표시한 부분만 바꿔줍니다.
예측할 기간에 따라서 숫자를 변경하는데, 이번 경우에는 IONIQ 은 12, AVANTE 는 12, SONATA 는 28 입니다.
모든 예측에 신뢰수준은 0.8을 사용합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
#standardSQL SELECT history_timestamp AS timestamp, history_value, NULL AS forecast_value, NULL AS prediction_interval_lower_bound, NULL AS prediction_interval_upper_bound FROM ( SELECT time AS history_timestamp, SUM(<strong>ioniq</strong>) AS history_value FROM bqml_tutorial.hmc GROUP BY time ORDER BY time ASC ) UNION ALL SELECT forecast_timestamp AS timestamp, NULL AS history_value, forecast_value, prediction_interval_lower_bound, prediction_interval_upper_bound FROM ML.FORECAST(MODEL bqml_tutorial.ga_arima_model_<strong>ioniq</strong>, STRUCT(<strong>12</strong> AS horizon, 0.8 AS confidence_level)) |
이제 결과가 어떻게 나올까요? 하나씩 살펴보시죠.
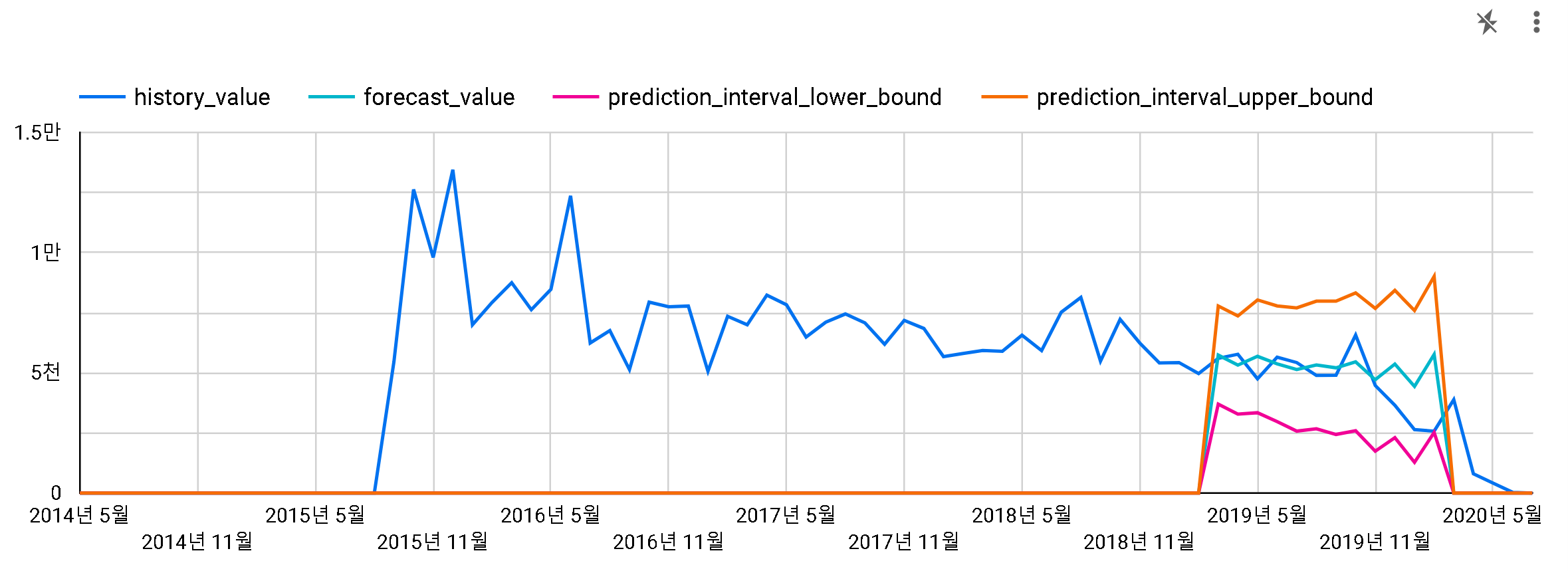
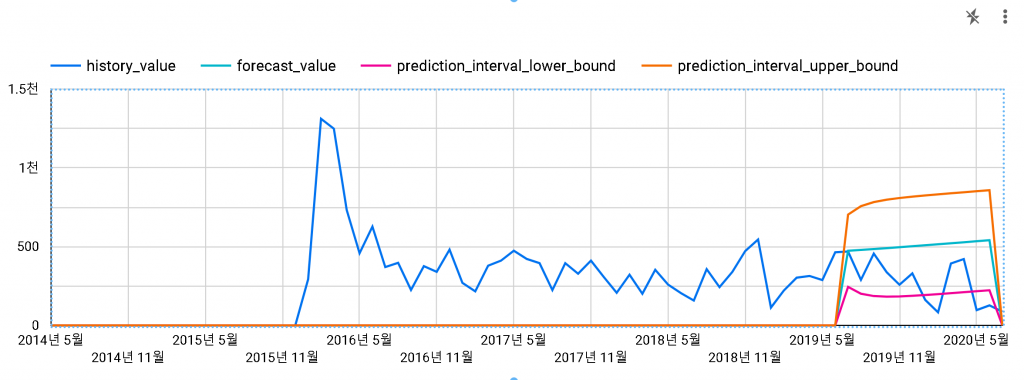
1) IONIQ (데이터 스튜디오로 보기)
2016-01부터 2019-07까지의 데이터로 모델링을 진행하고, 2019-08부터 12개월간의 예측을 진행했습니다.
과연 예측이 얼마나 맞을까요?
실 판매량이 파란색 그래프입니다. 에메랄드색이 예측값이고, 주황색이 신뢰상한, 핑크색이 신뢰하한입니다.
실 판매량이 예측값보다 항상 아래에 있지만 어느 정도 맞는 것 같습니다.
하지만, 아이오닉 세일즈팀에서는 이 결과를 별로 좋아하지는 않을 것 같네요.
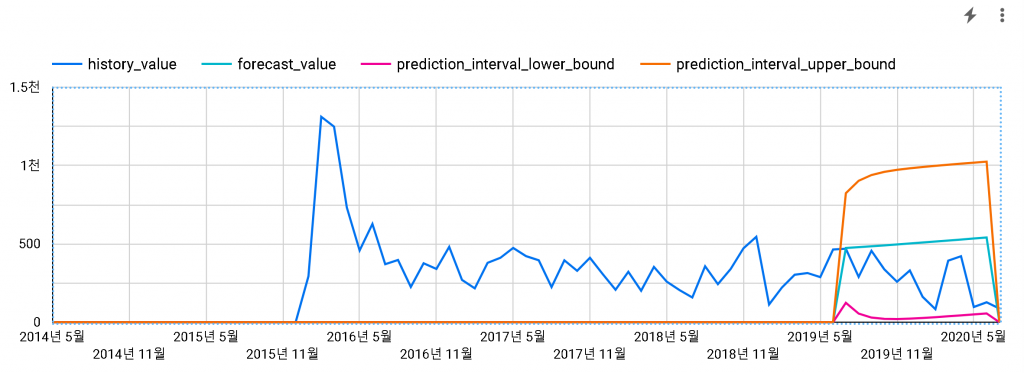
모델링에 사용한 데이터가 적은 편이라, 신뢰수준을 0.95로 올려보았습니다.
이번에는 모든 실 판매량이 상하한 범위에 들어옵니다.
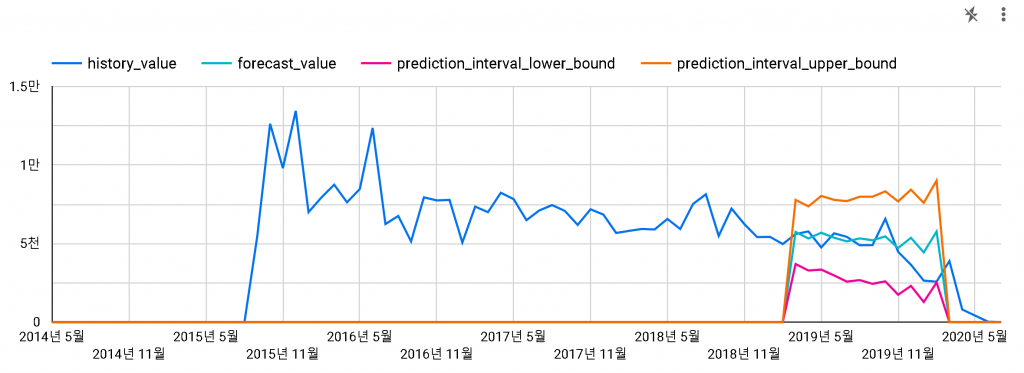
2) AVANTE AD (데이터 스튜디오로 보기)
2015-09부터 2019-03까지의 데이터로 모델링을 진행하고, 2019-04부터 2020-03까지 12개월간의 예측을 진행했습니다.
신형 아반떼가 2020-04에 출시하여서 이후 예측은 맞을 수가 없기에 제외했습니다.
이번 결과는 꽤 흥미롭습니다. 모델링에 사용한 표본의 수는 IONIQ과 동일한데, 더 정확한 예측이 되었네요.
2019년 12월부터 예측과 실제가 맞지 않는데, 신형 아반떼의 출시 예정일이 공개되고 코로나19로 경제가 위축되어서일까요?
그래도 2019년 3월 시점에서 약 8-9개월간의 미래 예측을 정확하게 할 수 있었다면 마케팅에 꽤 도움이 되지 않았을까 싶습니다. (물론 그렇게 예측하고 추진하고 있으리라 생각합니다. )
3) LF SONATA (데이터 스튜디오로 보기)
2014-04부터 2018-03까지의 데이터로 모델링을 진행하고, 2018-04부터 2020-07까지 예측을 진행했습니다.
2019-03에 후속 모델이 출시되었기 때문에 예측 데이터는 맞지 않을 것이지만, 어떤지 보기 위해 예측 기간을 길게 했습니다.
ARIMA 모델에서 일자와 시간은 TIMESTAMP 값으로 입력해야하는데, 구할 수 있는 데이터는 월 판매량이라 매월 1일로 월 판매량을 세팅해서 그런지, 예측일자들이 조금씩 밀려서 중간에 누락되는 월(2019-02)이 생긴 것 같습니다. 크게 문제는 안되는 것 같습니다.
예측 처음부터 잘 맞지가 않습니다. 예상보다 부진한 판매에 무슨 이유가 있을까요? (2018년 판매 부진에 대한 매경 기사)
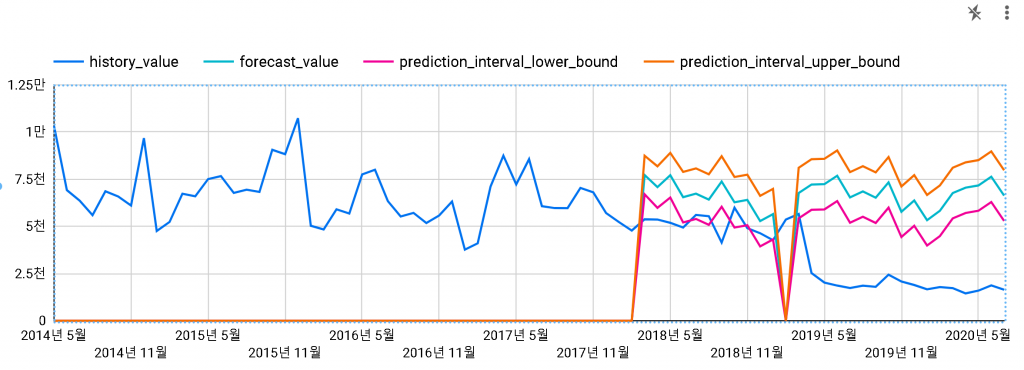
신뢰수준을 0.95로 올렸습니다. 상하한이 좀 더 늘어나게 되는데요. 그래도 겨우 맞습니다.
하한을 벗어나는 값이 있는 것은 좋은 결과는 아니겠죠.
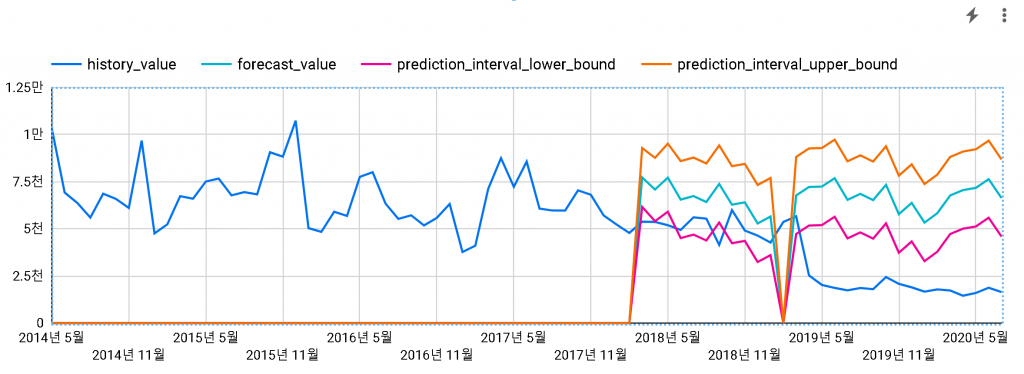
만약, 예측 값대로 판매가 되었다면 어떻게 되었을까요?
2018-04 ~ 2018-12 구간이 예측 값대로였다면, 2018년에는 총 75,233대를 판매했을텐데요.
그렇다면 총 판매순위가 7위에서 6위 쏘렌토를 제치고 한 단계 올라갔겠네요. 5위 아반떼 AD와도 근접하기 때문에 5위까지도 올라갔을지 모르겠습니다. (2018년 국산 차종 판매량 순위)
이번 포스팅을 통해서 ARIMA 모델 시계열 예측과 비교를 진행하기 위해서 여러 자료를 참고했었는데, 링크를 공유합니다.
Forecasting: Principles and Practice – 예측 데이터와 기법 : 판매량만을 가지고 미래를 예측하는 것의 한계는 존재함을 알려줍니다.
가장 단순한 시계열 예측 기법은 예측할 변수 정보만 이용하고, 변수의 행동에 영향을 미치는 다른 요인들을 고려하지 않습니다.
신뢰구간에 대한 설명 블로그 : 간단명료하게 설명해두어서 좋았습니다.
ARIMA Model – Complete Guide to Time Series Forecasting in Python : 파이썬을 사용하는 것은 아니지만, 그래프들이 이해하는데 도움이 되었습니다.